优化器(Optimizer) 是Oracle数据库中内置的一个 核心子系统 。
其目的是:按照一定的判断原则 来得到它认为的目标SQL在当前情形下最高效的执行路径 (Access Path)。
根据判断原则,可分为 RBO 和 CBO 两种类型的优化器:
RBO (Rule-Based Optimizer) :基于(内置的)规则 的优化器,规则 硬编码在Oracle数据库的代码中;CBO(Cost-Based Optimizer) :基于成本 的优化器,成本根据目标SQL语句所涉及的表、索引、列等相关对象的统计信息计算出来。以下是Oracle数据库里的SQL语句的执行过程 :
首先执行对目标SQL的语法、语义和权限的检查 ; 如果通过检查,Oracle会在Library Cache中查找匹配的Shared Cursor ;重用 其存储的解析树和执行计划 ; 10g后 ,Oracle会计算比较经过查询转换后的等价改写SQL的成本 和原始SQL的成本,低于才执行查询转换;接着根据不同的优化器类型,Oracle采取不同的判断原则,从查询转换后的诸多执行路径中选一条作为执行计划; 最后根据这个执行计划去实际执行该SQL,将执行结果反馈给用户。 Oracle一共有15个等级的执行路径,默认等级值低的执行路径的执行效率会比等级值高的执行效率要高 ;所以RBO会从决定目标SQL的执行计划中选择一条等级值最低的执行路径来作为执行计划。
开启RBO模式:
如果RBO选择的执行计划不是当前情形下最优的执行计划,有以下几个办法调整:
使用 RULE Hint 和 DRIVING_SITE Hint 可以调整RBO的执行计划且不自动启用CBO;
等价改下目标SQL:where条件中 对number 或者date 类型的列加0 ,
如果是varchar2类型的,加可以加个空字符串
对于执行路径一样的情况:假如出现执行路径一样 的情况,这时候就要根据数据字典缓存先后顺序 来确定等级,确定哪条作为执行计划。
通过调整相关对象在数据字典缓存中的缓存顺序 ,改变目标SQL中所涉及的各个对象在该SQL文本中出现的先后顺序来调整执行计划。
CBO 会从目标SQL诸多可能的执行路径中选择一条成本值最小的路径 来作为执行计划;
各路执行路径的成本值是根据目标SQL语句所涉及的表、索引、列等相关对象的统计信息 计算出来的;
成本 即 对执行目标SQL所要耗费的I/O、CPU和网络资源 的一个估算值 ;
即CBO 会认为消耗系统I/O和CPU资源最少的执行路径即最佳选择 。
表示对目标SQL的某个具体步骤的执行结果所包含记录数 的估算 ;
其值越大 ,对应成本值越大 。
其公式表示:
S
e
l
e
c
t
i
v
i
t
y
=
施
加
指
定
谓
词
条
件
后
返
回
结
果
集
的
记
录
数
未
施
加
任
何
谓
词
条
件
的
原
始
结
果
集
的
记
录
数
Selectivity =\frac{施加指定谓词条件后返回结果集的记录数}{未施加任何谓词条件的原始结果集的记录数} \quad
S e l e c t i v i t y = 未 施 加 任 何 谓 词 条 件 的 原 始 结 果 集 的 记 录 数 施 加 指 定 谓 词 条 件 后 返 回 结 果 集 的 记 录 数 ?
可见,可选择率为1时可选择性最差。
也可以这么表示:
S
e
l
e
c
t
i
v
i
t
y
=
C
o
m
p
u
t
e
d
?
C
a
r
d
i
n
a
l
i
t
y
O
r
i
g
i
n
a
l
?
C
a
r
d
i
n
a
l
i
t
y
Selectivity =\frac{Computed\ Cardinality}{Original\ Cardinality} \quad
S e l e c t i v i t y = O r i g i n a l ? C a r d i n a l i t y C o m p u t e d ? C a r d i n a l i t y ?
即 Computed Cardinality = Original Cardinality * Selectivity
在目标列没有直方图且NULL值的情况下,用目标列做等值查询的选择率是:
S
e
l
e
c
t
i
v
i
t
y
=
1
N
u
m
_
D
i
s
t
i
n
c
t
Selectivity =\frac{1}{Num\_Distinct} \quad
S e l e c t i v i t y = N u m _ D i s t i n c t 1 ?
从 Oracle 10g 开始,Oralce在解析目标SQL时,默认使用CBO 。
CBO在查询转换中做的第一件事,即对原目标SQL做简单的等价改写 (仅适用于CBO):
在原目标SQL上加上根据该SQL现有的谓词条件推算出来的新的谓词条件 。
简单来说就是从: a = b and b = c 推算出 ----> a = c.
不同模式下的计算成本值的方式不同
其控制参数为
RULE :使用RBO解析 CHOOSE:Oracle 9i的默认 使用值,只要该SQL中所涉及的对象 有一个有统计信息 ,那么解析该SQL时就会使用CBO First_Rows_n(n = 1, 10, 100, 1000 ):以最快的响应速度返回头n (n = 1, 10, 100, 1000 )条记录所对应的执行步骤的成本值修改为很小 的值 All_Rows :Oracle 10g及以后 的版本中的默认使用值,侧重于最佳吞吐量 (即最小的系统I/O和COU资源的消耗量) 指包含指定执行结果的集合
对于CBO 而言,对应执行计划中的Rows反映的就是CBO对于相关执行步骤所对应的输出结果集 的记录数(即Cardinality)的 估算值 。
是指Oracle在访问目标表里的数据时,会从该表所占用的第一个区(EXTENT)的第一个(BLOCK)开始扫描,一直扫描到该表的高水位线 ,这段范围内所有的数据块都必须读到。高水位线的副作用是,即使delete删除完了所有的数据,高水位线依旧保持原来位置。
Oracle在做全表扫描操作时会使用多块读 ,其执行时间一定会随着目标表数据量的递增而递增 。
ROWID :表的数据行所在的物理存储地址 ;
通过Oracle内置的ROWID伪列 得到对应的行记录所在的ROWID的值;
再通过 DBMS_ROWID包中的(
示例:7_166_0 ,即该行记录的实际物理存储地址位于7号文件的第166个数据块的第0行记录 。
首先了解下B树索引 :《Oracle索引介绍——关于Oracle索引的作用、具体分类、查看和修改》 B树索引是Oralce数据库中最常用的索引类型(也是默认的) ,它是以B树结构组织并且存放索引数据的。默认情况下,B树索引中的数据是以升序方式排序的。主要数据都集中在叶子节点块所指向的数据行 。
根节点块:索引顶级块,它包含指向下一级节点的信息。
分支节点块 :包含指向相应索引分支块/叶子块的 指针 和索引键值列 指针 块地址 RDBA,分为两种:Lmc ,Left Most Child 的缩写,每个索引分支块只有一个Lmc,它指向的分支块/叶子块 中的所有索引键值列中的最大值 一定小于 该Lmc所在索引分支块 的所有索引键值列中的最小值 ;分支块/叶子块 中的所有索引键值列中的最大值 一定大于或等于 该行记录的索引键值列中的最小值 ;(索引键值列可为不完整的被索引键值的前缀)
叶子节点块 :通常也称为叶子,它包含索引入口数据,索引入口包含索引列的值和记录行对应的物理地址。
在B树索引中无论用户要搜索哪个分支的叶块,都可以保证所经过的索引层次是相同的。
即 先访问相关的B树索引(从根节点定位到相关的分支块,再定位到相关的叶子块,再对叶子块执行扫描 ),然后根据访问该索引后的得到的ROWID,再回表去访问对应的数据行记录。
Oracel采用这种方式的索引,可以确保无论索引条目位于何处,都只需花费相同的I/O即可获取它 ,这就是为什么被称为B树索引。






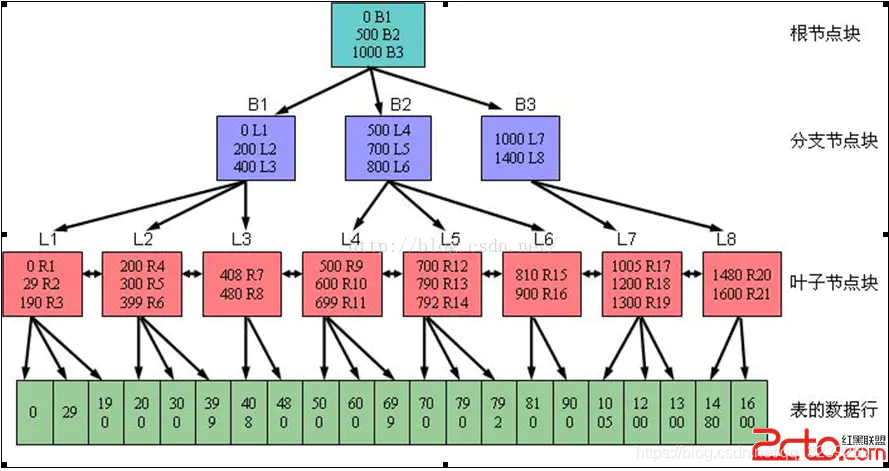 B树索引由根节点块、分支节点块和叶子节点块组成。其中主要数据都集中在叶子节点块所指向的数据行。
B树索引由根节点块、分支节点块和叶子节点块组成。其中主要数据都集中在叶子节点块所指向的数据行。


